LangGraph 多智能体协作实战:Supervisor、Worker 与状态交接怎么设计?
这篇文章记录了我在贵阳实验室的实战过程。我坚信,在技术下行的时代,程序员唯一的护城河就是通过 AI 建立属于自己的数字资产。
本文解决的问题
- LangGraph 多智能体系统什么时候需要 Supervisor?
- Supervisor Agent 和 Worker Agent 分别负责什么?
- 多个 Agent 如何共享 state,又不互相污染?
- Handoff 时应该传递哪些信息?
- thread_id、user_id、session_id 怎么设计?
- 多智能体任务失败后如何恢复?
适合谁读
- 已经用 LangGraph 做过单 Agent Workflow 的开发者
- 想把 AI Agent 从 Demo 推到生产环境的人
- 正在设计客服、销售、财务、代码审查等多 Agent 系统的人
- 遇到状态串线、任务交接丢失、Agent 死循环问题的全栈工程师
一、不要一上来就做多智能体
很多开发者在接触 AI Agent 的初期,容易被多智能体相互协作、自动对话的炫酷效果所吸引。但在实际生产环境中,盲目引入多智能体架构往往是灾难的开始。
我们必须明确一个核心原则:不是所有复杂任务都需要多智能体,很多任务一个 Agent 加上一组动态工具就足够了。
单 Agent 模式的优势与适用场景
如果你的任务符合以下特征,建议优先采用单 Agent 架构:
- 工具数量较少:通常在十个以内,模型可以清晰理解每个工具的用途和调用时机,不容易产生幻觉。
- 决策路径较短:任务的推进不需要跨越多个职责完全不同的专业领域。
- 状态相对简单:整个对话或执行链条中,需要维护的状态变量较少。
- 不需要强物理角色分工:任务的执行者不需要扮演截然不同的社会角色或安全权限级别。
在单 Agent 模式下,系统具有极高的确定性和较低的延迟,调试和日志追踪也异常简单。
什么时候必须跨越到多智能体系统?
当你的业务复杂度增长到单 Agent 难以支撑的瓶颈时,才是多智能体架构进场的最佳时机。多智能体系统在以下场景中具有不可替代的价值:
- 任务需要多个专业角色:例如在一个软件开发智能体系统中,需要有产品经理负责拆解需求、架构师负责设计接口、程序员负责编写代码、测试员负责运行测试。每个角色的知识底座和提示词偏好完全不同。
- 需要分阶段显式处理:不同阶段的中间产物差异极大,不适合在同一个上下文中混合处理。
- 权限隔离与工具限制:不同阶段的 Agent 拥有完全不同的工具访问权限。例如,财务核算 Worker 拥有数据库的只读权限,而转账 Worker 拥有资金划拨的写权限。如果不做物理角色隔离,单 Agent 在被注入攻击时,可能会越权调用敏感工具。
- 流程需要人工审批或失败恢复:复杂的业务链条中,某些节点需要暂停等待人类确认,或者在特定节点失败时需要执行定向重试,这在单 Agent 中会使得状态机设计异常复杂。
官方文档指出,多智能体系统用于协调专门组件处理复杂工作流。这说明多智能体不是为了看起来高级,而是为了物理隔离复杂性。
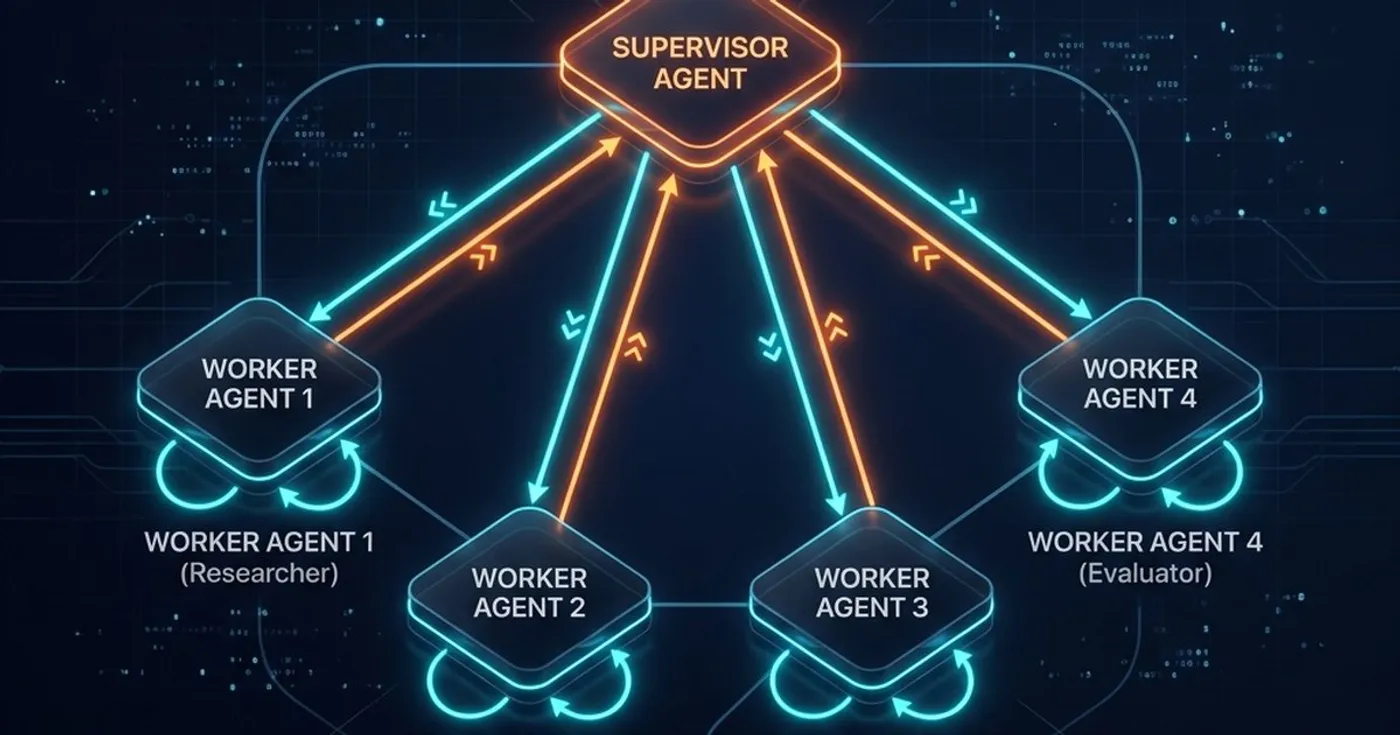
二、Supervisor / Worker 模式解决什么问题?
在多智能体系统的各种拓扑结构中,Supervisor / Worker 模式(层级多智能体系统)是最符合企业组织架构、也是最容易在生产环境落地的一种模式。
Supervisor / Worker 模式的本质,是把决策权和执行权物理分开。
传统群聊模式的弊端
在没有 Supervisor 的网状群聊模式(Peer-to-Peer)中,Agent 之间是扁平协作的。例如 Agent A 执行完后,把结果在信道中广播,由模型自主决定下一步谁来接力。这种模式存在三大致命问题:
- 决策不确定性:随着 Agent 数量增加,路由决策的幻觉概率指数级上升,极易出现 A 和 B 互相推诿或陷入死循环的情况。
- 上下文无限膨胀:每个 Agent 都被迫接收全量的聊天历史,Token 消耗呈平方级增长。
- 调试极其困难:由于没有统一的编排大脑,你很难说清某次错误的路由决策到底是谁的责任。
Supervisor 模式的破局机制
层级式架构通过引入一个强监督者来解决上述痛点:
Supervisor Agent 负责:
- 接收并理解用户的最终目标,将其拆解为子任务。
- 作为路由中枢,显式调度特定的 Worker 执行子任务。
- 审查 Worker 返回的结果,判断其是否达到了阶段性交付标准。
- 决策下一步走向:是继续指派下一个 Worker,还是进行局部重试,亦或是直接结束流程并输出给用户,甚至在无法决策时主动转人工。
Worker Agent 负责:
- 接收来自 Supervisor 的具体任务指令和局部上下文。
- 专注于执行单一专业领域的任务,调用该领域独有的工具集。
- 向 Supervisor 返回结构化、干净的执行结果。
- 坚决不参与系统级的全局流程控制,不越权修改全局路由状态。
通过这种职责划分,我们将复杂的路由决策集中在 Supervisor 的提示词中,而 Worker 则可以保持极度的专注与精简。这极大地提升了系统的稳定性和可维护性。
三、最小架构拓扑图
在 LangGraph 中,Supervisor 模式的节点拓扑可以用以下数据流向来表达:
┌────────── User ──────────┐
│ │ (输入 / 输出)
▼ ▲
┌──────────────────────────────────────┐
│ Supervisor Node │ (统一调度决策者)
└──────────────────┬───────────────────┘
│
│ (根据决策路由)
▼
┌─────────────┴─────────────┐
▼ ▼
┌──────────────┐ ┌──────────────┐
│ Research │ │ Coding │
│ Worker Node │ │ Worker Node │ (专项执行 Worker)
└──────┬───────┘ └──────┬───────┘
│ │
└─────────────┬────────────┘
│ (返回结构化产物)
▼
┌──────────────────────────────────────┐
│ State Merger / Edge │ (状态规整与回传)
└──────────────────────────────────────┘这个最小架构中,所有 Worker 的输入和输出都会重新汇聚回 Supervisor,由 Supervisor 判定是进入 END 状态,还是走向另一个 Worker,或者要求原 Worker 重新执行。
四、State 应该怎么设计?
多智能体系统里,State 不是简单的聊天记录列表(Message List),而是跨节点流转的业务对象。
在 LangGraph 中,State 通常是一个继承自 TypedDict 的 Python 字典。一个合理的、可用于生产级多智能体的 State 应当具备分层和模块化的设计。
推荐的全局 State 结构设计
from typing import TypedDict, List, Dict, Any, Annotated
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
class GlobalAgentState(TypedDict):
# 基础物理元数据
user_id: str
thread_id: str
session_id: str
# 任务控制流
task_goal: str
current_step: str
assigned_worker: str
# 全局对话历史(仅 Supervisor 共享)
messages: Annotated[List[BaseMessage], add_messages]
# 结构化业务产物(Worker 将结果写入此处,避免污染 message 历史)
worker_outputs: Dict[str, Any]
# 审计与异常记录
error_log: List[str]
approval_status: str # pending | approved | rejected
final_answer: str状态设计的铁律
为了防止多智能体在协同过程中把状态搞乱,你必须遵守以下三条铁律:
1. 不要让 Worker 直接改写全局流程状态
Worker 的职责是生产数据,而不是控制流程。在 LangGraph 中,Worker 节点应当返回它自己局部计算出的业务字段(例如 worker_outputs 中的一个子集),然后由 Supervisor 节点去读取这些产物,决定是否修改 current_step 或进行后续流转。
2. 不要把所有 message history 原封不动塞给每个 Worker
如果把全局的 messages 列表直接作为参数传给 Research Worker,模型会受到其他 Worker(如 Coding Worker)大量无关推理过程的干扰,不仅容易产生噪声幻觉,还会造成 Token 的极大浪费。每个 Worker 应当只接收与其当前子任务直接相关的上下文片段。
3. 不要让不同用户共享 thread_id
在设计全局 State 存储时,必须确保每个独立的任务线程拥有唯一的标识符。如果并发用户的请求共享了同一个 thread_id,LangGraph 的 State 会在多进程或多线程环境下发生严重的状态覆盖和数据串线。
五、Handoff 状态交接时应该传什么?
Handoff(任务交接)是多智能体协作中最为脆弱的环节。如果交接时信息不透明,下一个 Agent 就会丢失上下文;如果交接时信息冗余,又会导致模型理解错乱。
Handoff 不是把所有上下文粗暴地丢给下一个 Agent,而是传递足够完成任务的最小上下文。
Handoff 应当包含的字段
当 Supervisor 决定将任务分配给某个 Worker 时,应当构建一个精简的输入载荷(Payload):
- 明确的任务目标:例如,编写符合
api.py接口规范的单元测试代码。 - 上一步的明确结论:如,Research Worker 已经获取的第三方 API 数据字典。
- 当前 Worker 的明确职责:本次调用的核心任务。
- 允许使用的工具与限制:防止模型擅自执行超出边界的行动。
- 预期的输出结构:通知模型返回特定格式的 JSON,便于 Supervisor 解析。
状态交接 Payload 伪代码示例
# Supervisor 节点在路由分流时,为 Worker 封装的专用上下文
def route_to_worker(state: GlobalAgentState) -> Dict[str, Any]:
current_worker = state["assigned_worker"]
last_output = state["worker_outputs"].get("previous_step_result", "")
# 构建专属于该 Worker 的 Handoff 上下文
return {
"messages": [
{
"role": "system",
"content": f"你是一个专业的 {current_worker}。上一步的执行结果是:{last_output}。请基于此结果完成以下目标。"
},
{
"role": "user",
"content": state["task_goal"]
}
]
}坚决禁止传递的内容
在 Handoff 阶段,以下敏感或冗余的数据应当被过滤器物理剔除:
- 完整的、未过滤的全局聊天历史:排除无关 Agent 的碎碎念。
- 其他 Worker 的中间高维向量、庞大的日志文件或无关的数据库 dump。
- 敏感的系统级凭证、其他用户的 session 身份信息。
- 模型在上一阶段的思维链(CoT)推理草稿纸。只保留其最终输出的结构化结论。
六、如何避免状态串线?
在多智能体系统投入生产环境并面临高并发用户请求时,状态串线是发生频率最高、后果最严重的问题。用户 A 查到了用户 B 的私人数据,或者用户 A 的任务中途插入了用户 B 的对话上下文,这在企业级应用中是绝对不能容忍的。
状态串线通常不是模型推理出了问题,而是 thread_id、session_id、user_id 物理隔离设计混乱所导致的。
五大物理维度的严密定义
为了在系统设计层面彻底消除串线隐患,必须将系统的层级关系规整清晰:
user_id:标识唯一的使用者(例如usr_98231)。它是计费、流控和基本数据越权校验的底层依据。session_id:标识一次登录或会话生命周期(例如sess_00971)。用于隔离用户的单次交互上下文,通常在用户关闭窗口或超时后失效。thread_id:标识 LangGraph 状态机实例的唯一线程(例如thread_127a90bc)。它是 Checkpointer 读取和写入 State 的物理 Key。run_id:标识某次具体执行的生命周期。单次任务被唤醒、执行、挂起、再到结束的单次运行周期。request_id:标识一次具体的网络交互或外部工具调用接口。用于在分布式追踪(如 OpenTelemetry)中进行全链路日志聚合。
生产级高并发防串线架构
在部署生产级多智能体系统时,必须遵循以下防串线机制:
# 每次客户端请求到达时,网关必须强校验 user_id 与当前 thread_id 的绑定关系
def execute_agent_workflow(client_request: Dict[str, Any]):
user_id = client_request["user_id"]
thread_id = client_request["thread_id"]
# 安全屏障:校验此 thread_id 是否确实属于该 user_id,防止伪造 thread_id 越权访问
verify_thread_ownership(user_id, thread_id)
# 传入显式的 config 字典,LangGraph 会通过 thread_id 物理隔离持久化状态
config = {
"configurable": {
"thread_id": thread_id,
"user_id": user_id
}
}
# 唤醒图执行
app.invoke(
{"task_goal": client_request["prompt"]},
config=config
)在系统日志中,所有节点的 print 或 log 输出必须带上当前上下文的 thread_id 与 request_id。这样当多个用户的 Agent 节点并发执行时,开发人员可以通过日志服务(如 ELK)清晰地把每个用户的状态机轨迹过滤出来,而不会混淆在一起。
七、Checkpointer 在多智能体里起什么作用?
在单 Agent 系统中,我们或许还可以通过内存变量来记录短期对话历史。但在多智能体系统中,一个复杂的任务可能会运行几分钟、几小时甚至需要跨越几天(例如包含人工审核的审批流程)。
没有 Checkpointer(持久化检查点),多智能体系统一旦中断,就很难恢复到正确节点。
Checkpointer 的核心应用场景
Checkpointer 在层级多智能体协作中扮演着物理数据库的角色,解决以下生产难题:
- 人工介入审批(Human-in-the-loop):当 Supervisor 路由到转人工节点时,Graph 的执行流需要被物理挂起,State 被安全写入数据库。当管理员在后台点击批准后,系统读取
thread_id对应的检查点并无缝接续运行,不需要重新跑前置的 Worker。 - 长任务断点续跑:如果 Research Worker 在处理第十步时,网络接口突然超时崩溃,系统可以从第九步的 Checkpoint 重新唤醒,而不用从第一步重新拉取数据,避免重复消耗高昂的 Token 费用。
- 任务执行重试(Retry):当检测到特定 Worker 执行出错且符合重试策略时,系统可以选择回滚至上一个完好的 Checkpoint,进行有状态的自我修复。
我们在旧文《LangGraph Memory and Checkpointing for Production AI Agents》中已经深入探讨过 Checkpointer 的实现机制。在实际部署中,推荐使用基于数据库(如 SQLite 或 PostgreSQL)的持久化检查点。
在 Supervisor 模式下,当检测到某个高危操作(例如资金划转 Worker 被分配)时,可以在 Graph 节点间配置 interrupt_before:
# 构建 Graph 时,在执行资金划转节点前,物理暂停以待人工审批
workflow.compile(
checkpointer=memory_saver,
interrupt_before=["wire_transfer_worker"]
)八、常见错误与常见报错 (Error Logs)
1. Error: LoopLimitReached (死循环)
- 现象:Astro 或是 Python 端在运行多智能体图时报错,显示超过最大执行步数限制。
- 报错文本:
langgraph.errors.GraphRecursionError: Recursion limit of 25 reached. - 原因:Supervisor 在 Worker A 和 Worker B 之间迷失了方向。例如 Worker A 提供的结果格式不符,Supervisor 无法解析,却又没有 fallback 策略,便不断重复指派 Worker A。
- 对策:在 Supervisor 路由节点中设置强规则计数器,或者在
recursion_limit达到阈值前,强行将控制权路由到人工介入或回退节点。
2. Error: StateKeyMismatch (Worker 覆盖全局 State)
- 现象:Worker Node 运行完毕后,全局 State 中原本由其他 Worker 产生的数据被物理抹除或置空。
- 原因:Worker 返回了含有全局同名字段但值为空的字典,导致 LangGraph 的 State 默认更新合并策略直接覆盖了已有数据。
- 对策:仔细设计 State 的合并机制,或者对全局字段采用
Annotated的自定义追加/合并方法。例如,使用add_messages或者是带有去重逻辑的 Dict 合并函数。
3. Error: Invalid Thread Context (状态串线)
- 现象:高并发环境下,日志中出现以下多租户冲突错误。
- 报错文本:
ValueError: Thread context collision detected. Thread id '102983' already owned by user 'A', request came from user 'B'. - 原因:代码中没有对客户端传入的
thread_id执行属主校验,导致不同用户共享了同一个检查点。 - 对策:在 API 入口层强行增加权限拦截器,禁止跨用户访问检查点。
九、什么时候不要用多智能体?
多智能体架构绝对不是银弹。在以下场景中,建议坚决不使用多智能体:
- 任务仅需单次外部工具调用:例如,仅仅是让大模型查询一下天气并整理成表格。
- 业务决策树极短:流程非常固定,用常规的条件判断(If-Else)就能搞定,没有引入大模型自主路由的必要。
- 角色间不存在权限物理隔离:所有子任务在同一个权限上下文内执行,不存在敏感数据泄露风险。
- 对响应时间要求极高:多 Agent 协作会增加模型调用的交互次数,网络延迟和计算开销会成倍增长。
FAQ
LangGraph 多智能体和 CrewAI 有什么区别?
CrewAI 更像角色协作,适合快速搭建任务型 Agent,其内部协调逻辑主要依赖自然语言提示词;LangGraph 更像基于有向图的状态机,适合需要精确控制流程、自定义状态和具备物理 Checkpoint 恢复路径的生产级复杂系统。
Supervisor Agent 是否必须用昂贵的大模型?
不一定。如果你的任务路由逻辑非常固定,你可以直接用 Python 的规则代码(例如条件判断、关键词分类器)来充当 Supervisor 的角色,这被称为静态路由。只有当路由逻辑需要高维度的语义理解时,才需要使用大模型作为 Supervisor。
Worker Agent 能不能直接调用所有工具?
不建议。应当遵循最小特权原则。每个 Worker 应该只拥有完成自己任务所需的最小工具集,这是抵御 Prompt 注入攻击的物理防火墙。
多个 Agent 是否应该共享完整的聊天历史?
不建议。多智能体协作的核心是状态规整。Worker 之间应当通过结构化的 State 字段(如 Handoff Payload)来传递前置结论,而不是把成千上万 Token 的聊天历史一股脑传给每个模型。
Checkpointer 机制在高并发下会影响性能吗?
如果使用关系型数据库(如 PostgreSQL)读写高频的 State,会带来一定的 I/O 延迟。可以通过 Redis 做一层写缓存缓存层,或者仅在关键的 Handoff 和挂起节点执行持久化写盘,从而取得性能与安全性的平衡。
系列导航
LangGraph 生产级 Agent 编排实战系列:
- 第 1 篇:Supervisor / Worker
- 第 2 篇:状态隔离
- 第 3 篇:Human-in-the-loop
- 第 4 篇:失败恢复
- 第 5 篇:Observability
- 第 6 篇:Checkpointer
- 第 7 篇:Subgraph
