LangGraph Human-in-the-loop 实战:多智能体审批流怎么做?
这篇文章记录了我在贵阳实验室的实战过程。我坚信,在技术下行的时代,程序员唯一的护城河就是通过 AI 建立属于自己的数字资产。
本文解决的问题
- 在复杂的 AI 工作流中,如何防止智能体在无人值守时误调用高危、不可逆或高昂成本的工具。
- 如何在不打破有向无环图(DAG)状态流的前提下,实现状态的暂停、外界修改和继续运行。
- 在多智能体(Multi-Agent)协作系统中,如何划分 Supervisor、Worker 与人工节点之间的控制边界。
- 当人工干预拒绝了 AI 提出的方案后,系统应当如何回滚状态并安全终止或重新规划。
- 在并发多用户环境下,如何设计安全的数据路由,避免审批线程被交叉感染或串线。
适合谁读
- 已经熟悉 LangGraph 基础,正在尝试把智能体系统应用到实际业务场景的后台研发人员。
- 需要对接内部 OA、CRM、ERP 系统,且对数据安全性与操作可审计性有极高要求的系统架构师。
- 遭遇过模型“幻觉”误调用发送工具、删除工具而对自动化心存畏惧的独立开发者。
- 想要深入理解 LangGraph 状态持久化、检查点(Checkpointer)与有状态图编排底层机理的开发者。
一、 为什么生产级 Agent 不能完全自动执行?
六月的贵阳,暴雨砸在办公室的窗户上。桌上的 Mac Studio M2 Max 因为正在跑大规模多智能体回归测试,风扇发出了细微的呼呼声。我刚想端起咖啡,屏幕上的一行日志让我出了一身冷汗:由于模型对用户模糊指令的过度解读,分析 Worker 正在自动调用 write_database 工具,试图批量删除历史 CRM 记录。
在 Demo 阶段,智能体完全自动执行会让人觉得科技感十足。但如果真的进入生产环境,让 AI 拥有无限制的不可逆操作权限,就是灾难的开始。
生产环境下的高风险动作显而易见:
- 发送给重要客户的商业邮件。
- 数据库的物理删除或批量写操作(SQL 写入)。
- 财务系统的转账、扣款和发票生成。
- 正式生产环境的部署脚本执行与服务关停。
- 外部合同的电子签发或机密信息的导出。
这些场景如果交给大语言模型完全自主执行,只要出现一次概率性的模型幻觉,给企业带来的可能就是物理级别的商业损失。因此,在可逆的只读分析与不可逆的写入操作之间,必须建立一道硬性的人工隔离带。这就是 Human-in-the-loop(人机协同)存在的唯一理由。它不是对模型能力的妥协,而是工业级软件工程的必修课。
二、 LangGraph interrupt 解决什么问题?
在传统的流程编排中,要实现人工审批,我们通常需要破坏工作流的完整性。我们需要先将状态保存到临时数据库,强行终止当前进程,等待人工在后台页面点击确认后,再通过一个新的进程和入口把数据捞出来重新初始化。这种方式非常丑陋,不仅割裂了工作流逻辑,还让复杂的上下文跟踪变得异常痛苦。
LangGraph 原生提供的 interrupt 机制就是为了优雅地解决这一问题。它的本质是:在图执行(Graph Execution)的过程中,允许在任意节点直接发起挂起信号,中断当前的有向无环图运行,并向调用者返回一个需要人工审查的结构化载荷。
此时,Graph 会暂停,但它的所有上下文、状态变量和调用历史并不会消失,而是通过底层的检查点机制(Checkpointer)安全地封存在持久化数据库中。当人工在外部完成审批,或者修改了相关参数后,只需要携带相同的线程 ID(thread_id)发送恢复信号,Graph 就会从中断的地方无缝苏醒,顺着原有的拓扑结构继续执行。
这相当于给执行中的 AI 线程按下了物理暂停键。
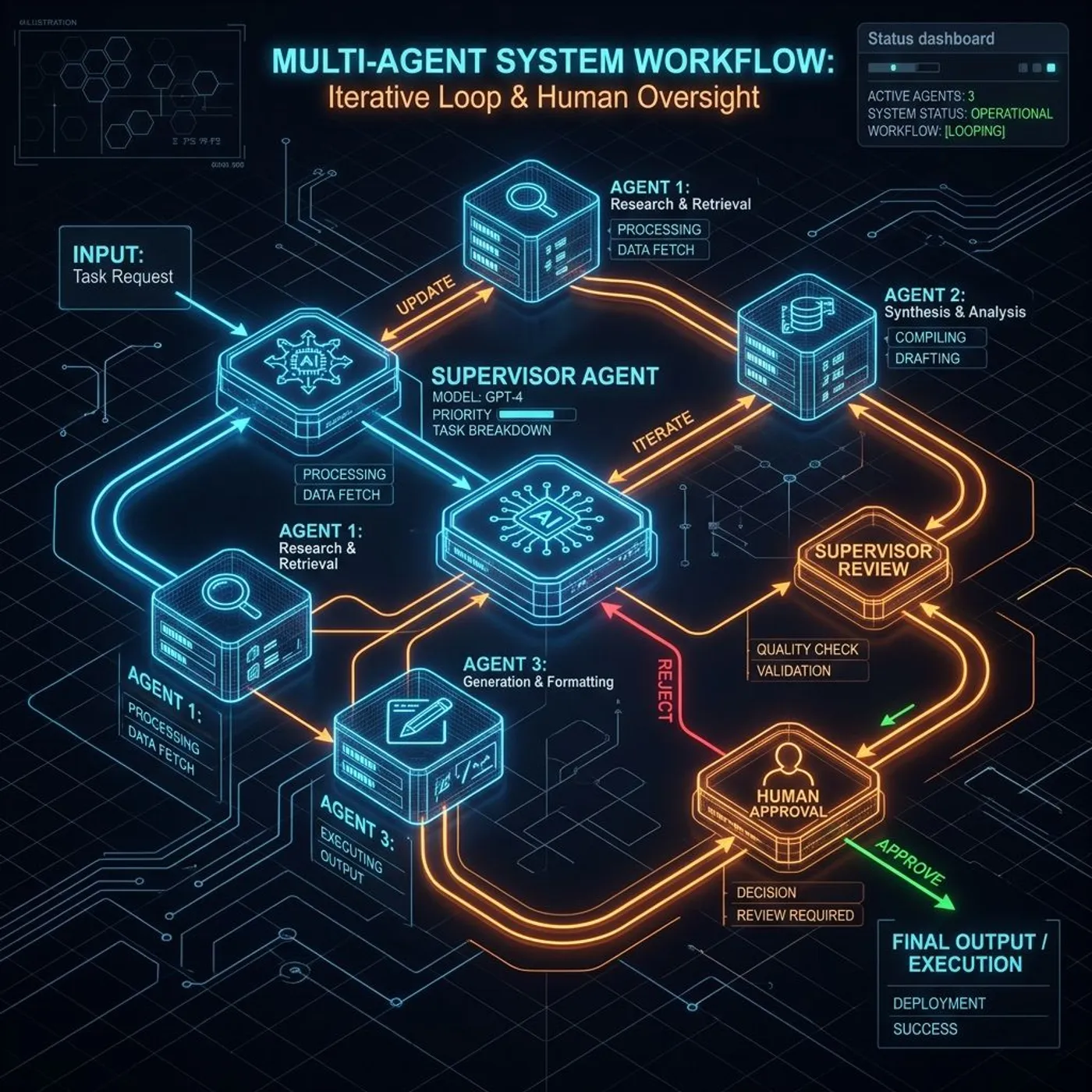
三、 审批流里 Supervisor 和 Worker 怎么分工?
在多智能体系统(Multi-Agent System)中,审批流的设计最忌讳的是 Worker 智能体各自为政。如果负责发邮件的 MailWorker 自行在其 Tool 内部触发 interrupt,不仅会让状态难以管理,还会导致系统的耦合度极高。
我认为,合理的生产级审批架构应该遵循下述分工原则:
Supervisor 智能体作为中心大脑,掌握全局的任务风险评级和路由逻辑。Worker 智能体作为专项任务的执行工具,只负责生成结构化的提案(Proposed Action),本身不直接拥有任何物理写工具的权限。
举个例子,当用户提出“给客户发送上月财报”时:
- Supervisor 收到请求,调用 AnalyticsWorker 整理数据并起草邮件。
- AnalyticsWorker 完成工作,但它不直接调用 send_mail 工具。相反,它返回一个标准格式的结构化数据,声明自己起草的内容以及需要人工确认的标记。
- Supervisor 接收到 Worker 的返回,检测到 requires_approval 为 true,随后在 Supervisor 的决策节点中触发 interrupt 挂起。
- 外部人工完成审批后,Supervisor 根据审批结果(通过/拒绝/修改),决定是将任务分发给具体的 Executor 工具节点去执行,还是退回 Worker 重新规划。
我们可以为 Worker 的提案输出定义一个严密的 JSON 契约:
{
"action_type": "send_email",
"risk_level": "high",
"target": "client@example.com",
"summary": "向客户发送 5 月份投资复利审计报告",
"proposed_payload": {
"subject": "5月度AltStack资产审计报告",
"body": "您好,附件为您的 5 月度投资回报明细,请查收。"
},
"requires_approval": true
}四、 审批节点应该长什么样?
审批节点(Approval Node)在底层不是一个简单的交互式弹窗,而是一个具备完整生命周期、可追溯、可审计的数据实体。
当我们在 LangGraph 中定义一个审批节点时,该节点至少要向外部展示以下结构化数据,以便被前端页面或 OA 系统正确解析渲染:
{
"approval_id": "appr_9x882a17f",
"user_id": "usr_9921",
"thread_id": "th_langgraph_hil_003",
"run_id": "run_8b11c9f2",
"proposed_action": {
"tool_name": "send_email",
"payload": "..."
},
"risk_level": "critical",
"created_at": "2026-06-12T09:56:00Z",
"approval_status": "pending"
}在后端,审批状态的演转应该是一条单向的单色轨道。它的初始状态必然是 pending,经过人工交互后,根据操作行为分化为以下几种结果:
- approved:审核通过,直接将数据投递给后续工具执行节点。
- rejected:审核拒绝,终止该工具的调用,并将拒绝理由写回图状态,交由 Supervisor 决定是否退回重写或直接向用户报错。
- edited:审核人员认为提案的大体逻辑对,但局部细节有瑕疵(例如邮件有错别字,或者 SQL 的 limit 条件太宽),直接修改了 proposed_payload 中的数据,随后提交执行。
- expired/cancelled:审批超时失效或人工撤销。
五、 approve / reject / edit 三种结果怎么处理?
在 LangGraph 的节点逻辑中,我们需要利用图的状态(State)来传递人工的审核意见。以下是处理这三种决策的硬核实现机制。
首先,我们定义图的全局状态结构。在 src/types/ 或直接在定义中:
from typing import TypedDict, Optional, Any
class AgentState(TypedDict):
task: str
proposed_action: Optional[dict]
action_result: Optional[dict]
approval_status: Optional[str] # approved | rejected | edited
approval_response: Optional[Any]当图执行到关键的审批前节点 prep_approval_node 时,我们通过调用 interrupt 触发图的挂起。
from langgraph.errors import NodeInterrupt
def prep_approval_node(state: AgentState):
action = state.get("proposed_action")
if action and action.get("requires_approval"):
# 触发硬性挂起,向调用者传递需要审核的数据包
raise NodeInterrupt({
"message": "请确认高危操作",
"proposed_action": action
})
return {}在外部,图执行中断,API 返回了挂起信息。外部的控制台或审批系统展示界面。当审批人员做出决定后,我们通过 update_state 写入审批结果,并使用 resume 恢复图的执行。
在恢复后的下一个节点 execute_action_node 中,我们必须编写防御性的决策逻辑来分流处理:
def execute_action_node(state: AgentState):
status = state.get("approval_status")
action = state.get("proposed_action")
# 严格防御:无明确批准标记,绝不调用任何写工具
if status == "approved":
# 正常调用真实执行工具
result = call_real_tool(action["tool_name"], action["proposed_payload"])
return {"action_result": result, "approval_status": None}
elif status == "edited":
# 获取人工修改过的载荷进行执行
edited_payload = state.get("approval_response")
result = call_real_tool(action["tool_name"], edited_payload)
return {"action_result": result, "approval_status": None}
elif status == "rejected":
# 拒绝路径,拒绝调用工具,将信息反馈给 Supervisor 重新规划
reason = state.get("approval_response", "人工拒绝")
return {
"action_result": {"status": "failed", "error": f"审批未通过: {reason}"},
"approval_status": None
}
else:
# 未知状态,安全阻断并强制报错
raise ValueError("安全策略阻断:未检测到合法的审批标记,拒绝执行高危工具。")通过这样的逻辑设计,系统在不解构 DAG 结构的前提下,通过更新 approval_status 实现了对分支路径的安全控制。
六、 Checkpointer 在审批流里起什么作用?
在探讨 Human-in-the-loop 时,很多开发者容易忽略检查点(Checkpointer)的存在。实际上,要是没有一个可靠的持久化检查点系统,任何审批流在生产环境中都会变得形同虚设。
为什么这么说?因为 interrupt 挂起只是当前计算线程的内存行为。如果你的 Agent 服务是跑在容器(如 Docker)中,或者是在云端 Serverless 架构下:
- 当审批人打开网页进行审查时,可能已经是几个小时之后了。
- 此时,原来的计算进程由于超时或者容器重启,可能早就被物理销毁了。
- 如果没有 Checkpointer,那么之前的所有执行状态、变量和上下文就会随着内存释放而烟消云散。
Checkpointer 的作用,就是在触发 interrupt 的那一瞬间,自动把当前的图状态(State)、所有节点跑完后的 Checkpoint 数据,全部序列化并写入到物理数据库中(比如 Redis, SQLite 或 PostgreSQL)。
当外部审批完成,发送更新信号时,你只需要指定 thread_id:
- 系统根据 thread_id 从数据库里捞出当时挂起那一刻的历史快照。
- 将图的反序列化状态重新装载进内存。
- 将外部写入的审批状态合并进当前状态。
- 从当时中断的那个 Node 开始,向下执行后续的流程。
这也就意味着,Checkpointer 提供了状态跨越时空和物理进程进行复活的能力。在生产部署中,应始终使用有状态的持久化检查点机制。
七、 多用户审批流如何避免串线?
如果在开发中设计不周,在多用户高并发场景下,极易发生“审批串线”的严重安全事故:用户 A 批准了某项操作,结果却被应用到了用户 B 的 thread_id 线程中,导致用户 B 的资金被误转走,或者是其数据被误删。
为了绝对避免这种串线事故,必须在架构设计层面将下述变量进行多重的强行绑定校验:
user_id + thread_id + run_id + approval_id在状态持久化和图更新时,我们必须坚持以下的设计铁律:
- 绝对不鼓励在没有校验 thread_id 的情况下,全局通过一个通用的 approval_id 去更新状态。
- 每一个审批任务生成的 proposed_action 中,必须显式携带当前的 thread_id 和 reviewer_id。
- 当审批结果通过 Webhook 写回时,接口层必须先通过当前登录的用户 Session 校验该用户是否拥有此 thread_id 对应会话的读写权限,验证通过后方可执行 state_update 写入操作。
- 在保存日志时,强制将操作人 reviewer_id 与审批时间戳 timestamp 写入数据库快照,作为后续合规性审计的铁证。
八、 哪些工具必须进入审批?
为了在安全性和工作效率之间取得精巧的平衡,我们不能对所有的工具调用都采取一刀切的审批策略。这样做会让审核人员被海量的微小待审批弹窗淹没,最终导致审批流流于形式(审核人会闭着眼疯狂点 approve)。
我认为应当将工具库划分为三级风险边界:
1. 允许自动执行的低风险工具(无副作用,只读)
这类工具通常不改变任何系统状态,只进行检索和分析。可以完全对 AI 开放,无需人工确认。
- read_file(读取文件)
- search_knowledge_base(检索知识库)
- call_weather_api(天气查询)
- text_classification(分类)
- format_data(格式化)
2. 建议审批的中风险工具(有轻微副作用,可逆)
这类工具会产生外部行为或修改局部业务系统,但仍属于可以通过后续手段进行覆盖或回退的范围。
- update_crm_contact(更新联系人电话)
- create_draft_article(创建文章草稿)
- send_internal_slack_message(发送内部通知)
- calculate_compound_interest(复杂理财数值预估写入)
3. 强制审批的高风险工具(不可逆,高成本)
一旦执行,会对物理世界、企业资产或核心数据产生无法恢复的改变,必须由人工在系统层面进行强行校验和确认。
- delete_database_record(物理删除数据)
- execute_raw_sql(执行原始 SQL 语句)
- send_client_email(直接向外部客户发送邮件)
- transfer_funds(财务转账)
- publish_to_production(向生产环境发布代码或数据)
九、 常见错误
在开发 LangGraph 人机协同审批流时,有几个非常经典的“坑”,我已经替大家踩过了:
常见坑 1:只在前端做拦截保护,后端 Tool 接口裸奔
这是最常见也最危险的安全漏洞。开发者仅仅在前端写了弹窗让用户点“确定”,但在图的后端实现中,执行工具的接口根本不校验 approval_status 状态值,只要接收到模型调用指令就直接执行。这种做法只要遇到网络波动、前端刷新或直接用 API 请求绕过,安全网就会瞬间漏风。
- 解决办法:在 Tool 执行的 Python/Node 真实代码层,必须强制进行二次断言校验。
常见坑 2:Worker 智能体直接拥有写工具权限
有些设计中,Worker 节点直接把 send_mail_tool 作为其可用工具。这会导致 Worker 在执行中绕过了 Supervisor 的风控路由,自我完成调用。
- 解决办法:Worker 只输出结构化的 Action 提案,统一交给有风控逻辑的 Supervisor 或专门的审批路由来进行过滤分发。
常见坑 3:在触发 interrupt 时抛出非持久化异常
如果在挂起时没有配合配置底层的持久化库,会导致在进程漂移或多 pod 负载均衡下,审批回来后找不到原来的状态快照,控制台输出类似的异常日志:
langgraph.errors.CheckpointNotFoundError: Checkpoint with thread_id 'th_003' and checkpoint_id 'cp_9a2f1' was not found in database.- 解决办法:确保在开发和生产环境中,为 Graph 初始化时传入了持久化的
SqliteSaver、PostgresSaver或RedisSaver实例,并且 thread_id 的生成规则全局唯一。
十、 最小上线检查清单
在你的多智能体审批系统合并代码并部署上线前,请对照下述清单进行最后的物理核对:
- 工具库是否完成了只读、可逆写入、高危写入的三级分级?
- 所有高危工具是否在后端执行代码中进行了 state.get(“approval_status”) == “approved” 的硬编码断言?
- 挂起(interrupt)逻辑是否与持久化存储(Checkpointer)绑定,并支持跨 Pod 状态恢复?
- thread_id 是否与用户会话 user_id 进行了强行校验,是否存在权限越权漏洞?
- 审批状态机是否完整覆盖了批准(approved)、拒绝(rejected)与人工修改(edited)三种流程?
- 当人工拒绝(rejected)后,图是否能安全地退回到 Supervisor 规划节点或输出安全失败结果,而不是卡死在原地?
- 数据库中是否设计了用于记录 reviewer_id、approved_at、request_payload 的审计日志表?
- 在并发测试中,多用户同时触发审批,是否会产生状态污染或 thread 交叉?
FAQ
LangGraph Human-in-the-loop 和普通的前端确认弹窗有什么本质区别?
普通弹窗只是在交互层进行阻断,如果用户刷新网页或者网络中断,状态就丢失了,甚至可以被直接绕过。LangGraph 的 Human-in-the-loop 是将暂停和恢复能力下沉到了底层的图状态引擎和检查点(Checkpoint)中,即使服务断电重启,也能通过 thread_id 完美恢复,是协议级和引擎级的阻断。
审批挂起后,图在等待过程中会持续消耗 Token 吗?
不会。当图执行到挂起节点抛出 NodeInterrupt 异常后,当前的执行进程就已经安全退出,状态也被写入到了数据库中,整个系统不再进行任何计算,因此绝对不会消耗大模型的 Token。只有当外部接收到审批结果并调用 resume 恢复执行时,才会重新拉起图并继续进行模型交互。
在多智能体系统中,人工修改(edit)后的载荷怎么传回给 Agent 状态?
你可以在调用 update_state(thread_id, values, as_node="prep_approval_node") 时,将修改后的 payload 字典直接写入到图的全局 State 状态的 approval_response 键中,然后在执行节点从 state.get("approval_response") 中读取这个人工修改过的参数,传给真实的 Tool 去执行。
系列导航
LangGraph 生产级 Agent 编排实战系列:
- 第 1 篇:Supervisor / Worker
- 第 2 篇:状态隔离
- 第 3 篇:Human-in-the-loop
- 第 4 篇:失败恢复
- 第 5 篇:Observability
- 第 6 篇:Checkpointer
- 第 7 篇:Subgraph
