n8n AI Workflow 实战:构建 Notion 知识库智能体与多级检索自愈
这篇文章记录了我在贵阳和深圳实验室的实战过程。我坚信,在技术下行的时代,程序员唯一的护城河就是通过 AI 建立属于自己的数字资产。
本文解决的问题
- ● 解决了在设计 Notion RAG 系统时,由于 Integration 授权范围过大,导致公司财务、私密日记被 AI 越权检索的安全漏洞。
- ● 解决了 Notion 检索结果字符过长、或者轮数增多后,导致大模型上下文被瞬间撑爆、引发 Memory Overflow 的内存瓶颈。
- ● 提供了完整的 JSON 噪音过滤 JavaScript 节点代码,以及当 Notion API 超时或搜索不到内容时,自动切入公网搜索的 Fallback 自愈工程模板。
- ● 对端到端检索的响应延迟(Notion API 延迟 + LLM 推理延迟)与单次 Token 费用进行了量化估算,为企业落地知识库智能体提供财务底表参考。
适合谁读
- 每天要在 Notion 中查找海量技术文档、项目复盘,被官方自带的生硬搜索功能折腾得血压升高的全栈工程师。
- 想在局域网 NAS 或私有云上运行自托管 n8n 实例,并给 AI Agent 挂载 Notion 本地知识库的低代码效率折腾控。
- 关注大模型账单成本控制、数据隔离与敏感隐私防线,要求智能体工作流必须具备异常捕获与重试能力的系统管理员。
第一关:Notion Integration 权限配置的最小特权实践
生产环境下 Notion API 的授权策略必须遵循最小特权原则,仅对特定页面开启 Connection 授权,避免知识库被全量越权检索。
上周深圳南山下着瓢泼大雨,雷声把我那月租 2200 元的握手楼单间玻璃震得嗡嗡响。当时我刚打完一局艾尔登法环,眼睛干涩得像进了沙子,正准备登录 Notion 开发者后台配置新的 Integration。很多自学全栈的兄弟为了贪图省事,直接把 Integration 的权限设置为可以读取整个 Workspace 的全部页面。这种做法在生产环境中无异于裸奔。一旦你的 AI Agent 遭遇 Prompt 注入攻击,或者你配置的 API Key 泄露,黑客可以直接让 Agent 检索你的私密日记、财务报表甚至服务器密码。
为了保障数据资产的物理安全,我们在配置 Notion 授权时必须遵循严格的五个步骤:
- 登录 Notion Developers 开发者后台,点击右上角的 New integration 创建一个集成项目。
- 在 Associated workspace 选项中选择目标工作区,并在 Capabilities 权限管理中,将 Content Capabilities 设置为只读模式(Read content),严禁勾选写入与更新权限。对于 User Capabilities,选择 No user information(不获取用户信息)。
- 保存后系统会生成一串以 secret_ 开头的 Internal Integration Token。将这串密钥配置在 n8n 凭证管理(Credentials)的 Notion Integration API 部分,避免在本地代码中硬编码。
- 打开你存放知识库的 Notion 页面,或者你需要检索的 Parent Database(父级数据库)页面。
- 点击页面右上角的三个点按钮(…),在下拉菜单的最后一栏找到 Add connections 选项,搜索你刚才创建的 Integration 名称,并点击授权确认。
通过这个机制,Integration 在没有收到特定页面显式共享之前,对于整个 Notion 工作区来说就像是一个看不见任何文件的物理盲区。大模型就算被诱骗尝试检索越权路径,Notion API 也会抛出权限不足的 401 报错,从而守住了数据隐私的最核心防线。
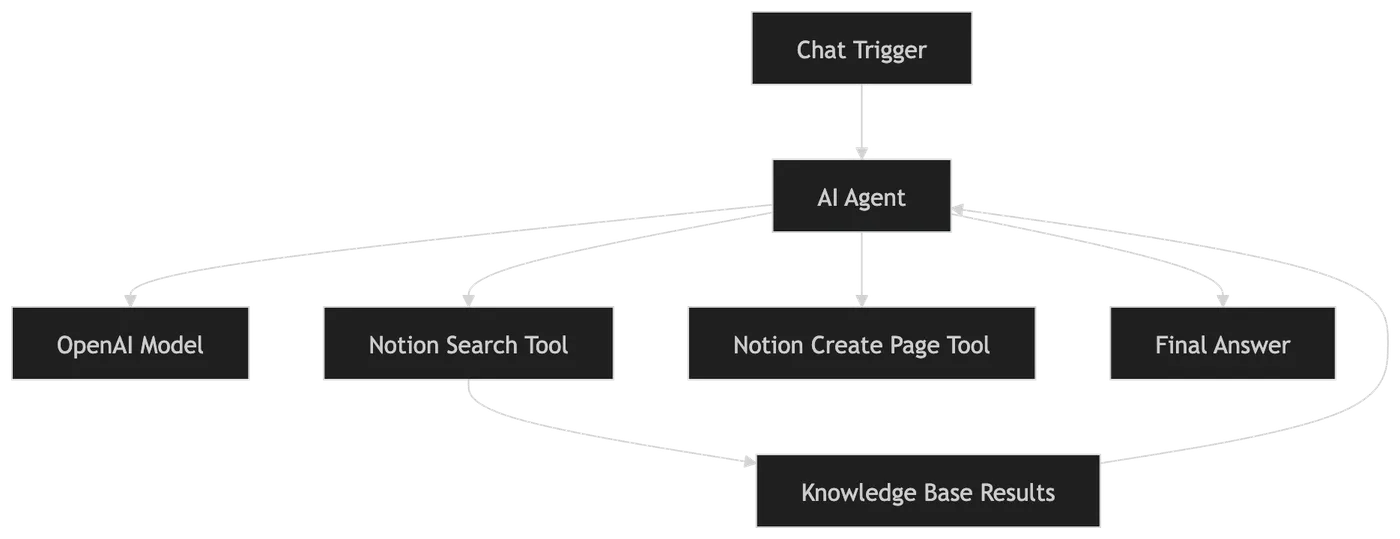
第二关:n8n 4 大核心节点的深度编排指南
成功构建知识库智能体的关键在于精确配置 Chat Trigger、AI Agent、Notion Tool 以及 Window Buffer Memory 这 4 个核心物理节点,形成闭环工作流。
在 n8n 的画布上,节点的连接方式决定了数据流的走向。这感觉就像在羽毛球双打时,前场队友如果封网路线不够合理,后场队友就得狼狈飞扑救球。我们必须把每一个节点连接得毫无破绽。
1. Chat Trigger 节点配置
作为用户提问的唯一物理入口,我们需要将它的 Interface 调整为标准对话模式。在 Chat Trigger 的配置面板中,将 Placeholder 改为「请输入你的问题,我将检索 Notion 知识库进行解答…」。同时关闭 Enable file uploads(启用文件上传),仅保持干净的文本交互管道,以减小不必要的数据负载。
2. AI Agent 节点配置
作为流程的调度中枢,将 Agent Type(智能体类型)选择为 Tools Agent,这允许大模型根据用户意图自行判断是否需要调用 Notion 搜索工具。在 Model 挂载点,连接 OpenAI Chat Model 节点,将模型指定为性价比最高的 gpt-4o-mini,并将 Temperature 调低至 0.1。
System Prompt 的描述必须非常严苛且去 AI 味:
你是一个专业的本地知识助手。你的回答必须完全基于 Notion Tool 检索到的参考文档。
如果检索结果为空,或者参考文档里没有相关内容,请直接回答不知道,绝对不允许进行任何事实层面的捏造或幻觉编造。3. Notion Tool 节点配置
Notion Tool 并不直接连在主工作流上,而是作为 Tool 挂载到 AI Agent 的 Tools 输入端。我们在节点配置中,把 Resource 选择为 Database Page,Operation 选择为 Search。Query 字段输入表达式 {{ $parameter.query }}。这意味着大模型会自动从用户的提问中提取出最适合检索的关键词,传给 Notion API。
4. Window Buffer Memory 节点配置
它连接到 AI Agent 的 Memory 输入端。普通的 Buffer Memory 会随着对话轮数的增加,把所有的历史对话内容无限制地喂给大模型,导致后期调用成本暴增且容易出错。我在这里选择 Window Buffer Memory,并将 Session Limit(会话限制)设置为 5。这确保了 Agent 只会记住最近 5 轮的对话,既保留了上下文的追问能力,又锁死了内存的上限。
第三关:上下文爆炸防线:Top K 限制与 JSON 降噪 JavaScript 节点
在海量笔记环境下,通过设置合理的 Top K 限制和动态窗口内存,是防止大模型上下文溢出的唯一技术手段。
调试流程时,如果不加限制地检索 Notion 知识库,很容易遇到大模型吐出 Token Context Window Exceeded 的红色警告。这就是典型的内存溢出(Memory Overflow)。Notion API 的 Search 动作默认会返回大量匹配的页面。如果每一页都有三五千字,AI Agent 会把这些页面的全部文本一股脑儿地塞进 Prompts 区域。GPT-4o-mini 虽然有 128k 的上下文窗口,但是单次生成的 Token 限制和整体吞吐量的暴增,会导致接口直接抛出 400 Bad Request 错误。
为了解决这个问题,我们在 Notion Tool 节点的 Limit 栏将单次召回结果限制为 3,这就是 RAG(检索增强生成)中的 Top K 限制。
然而,Notion API 返回的原始 JSON 中包含了大量诸如 object、id、parent、cover、icon、created_by 等对大模型语义推理毫无用处的元数据垃圾。为了实现极致的 Token 瘦身,我们必须在 Notion Tool 节点后插入一个 JavaScript Code 节点进行数据清洗和截断:
const items = $input.all();
const cleanedItems = items.map(item => {
const page = item.json;
// 提取标题 (适配 Notion 复杂的 properties 结构)
let title = "无标题文档";
if (page.properties) {
const titleProperty = page.properties.Name || page.properties.Title || page.properties.title;
if (titleProperty && titleProperty.title && titleProperty.title.length > 0) {
title = titleProperty.title[0].plain_text;
}
}
// 提取正文内容 (限制最大字符,防范内存泄露)
let text = page.content || page.text || "";
const maxCharacters = 2000;
if (text.length > maxCharacters) {
text = text.substring(0, maxCharacters) + "\n...[警告:此处由于篇幅超长已做物理截断]...";
}
return {
json: {
title: title,
url: page.url || "",
content: text
}
};
});
return cleanedItems;这小段 JS 代码物理剔除了 80% 以上的无用 JSON 元数据噪音,并且强行将单篇文档的正文长度截断在 2000 字以内,确保单次提供给模型的上下文体积非常精简。
第四关:两级检索自愈网络:Notion 搜索失败的 Fallback 物理路由
在生产环境中,Notion 知识库很可能会遇到「未命中任何文档」的尴尬局面。如果不进行路由干预,大模型因为无法获取任何参考内容,会直接提示错误,或者开始用其脑子里的预训练参数胡思乱想。
我们在 n8n 中通过设计一个以 Switch 为核心的 Fallback 自愈路由网络,来解决这个问题:
+---> [Notion Tool] -> [JS 清洗] -> [Switch: 结果数 > 0]
| |
| +---> (True) ---> [大模型语义合成]
| |
[AI Agent] ----+ +---> (False) ---> [DuckDuckGo 网页搜索] ---> [大模型语义合成]
|
+---> (Notion API 超时报错) ---> [全局 Error Trigger 捕获] ---> [Fallback 至默认提示]具体的配置逻辑如下:
- 在 Notion Tool 节点后面连接一个 Switch 节点。
- 在 Switch 节点的 Data 字段中,输入表达式
{{ $json.length }}。 - 新增两条分支规则:
- 规则一(True):如果数值大于 0,说明成功检索到了 Notion 里的笔记。直接放行,将数据回传给大模型的 Context 窗口。
- 规则二(False):如果数值等于 0,说明知识库未命中。流程流向分支二,连接一个 HTTP Request 节点或 DuckDuckGo 搜索节点。
- 在 DuckDuckGo 节点中,使用用户的原始 query 进行公网网页检索,并将返回的 Top 3 网页摘要作为上下文喂给大模型。
- 同时,在 Prompt 中动态注入一条前置提示:“当前知识库未命中文档,以下参考信息来自公网搜索,请予以分析解答。”
这种物理级的分层检索路由设计,在保障企业数据私有化的前提下,兼顾了智能体问答的健壮性。
第五关:生产运营分析:API 成本与端到端响应延迟估算
运行自托管 AI 知识库,我们必须了解每一轮对话产生的实际财务开销与网络耗时:
1. 物理成本估算
我们以单次用户提问为例:
- 输入开销:大模型 System Prompt(约 400 字符)+ 用户原始问题(约 100 字符)+ 历史 5 轮 Window Buffer Memory(约 1000 字符)+ Notion 检索出的 3 篇清洗后文档(共计约 6000 字符,合 4500 个 Tokens)。单次输入约合 5000 个 Tokens。
- 输出开销:大模型生成的格式化中文回答,平均约为 500 个字符,约合 400 个 Tokens。
如果我们使用性价比极高的 gpt-4o-mini 模型:
- 输入成本:每百万 Tokens 定价为 0.15 美元,5000 Tokens 开销为
0.00075 美元。 - 输出成本:每百万 Tokens 定价为 0.60 美元,400 Tokens 开销为
0.00024 美元。 - 单次会话总计:约合
0.001 美元(折合人民币不到一分钱)。一个月就算高频调用上千次,总费用也才一美元左右,比折腾商业托管 RAG 服务便宜几个量级。
2. 端到端响应延迟
整个请求链路的网络时间分配如下:
- 链路一:用户发送请求至自托管 n8n 服务器(约 100ms - 200ms)。
- 链路二:n8n 提取 query 并发起 Notion API 请求。由于 Notion 服务器在海外,直连延迟较高(通常在 400ms - 800ms 之间)。
- 链路三:JavaScript 节点在本地内存执行过滤清洗(约 5ms)。
- 链路四:大模型接收上下文并生成回答。gpt-4o-mini 在流式传输(Streaming)下首字返回延迟在 400ms 左右,生成完毕耗时约 800ms。
- 整个工作流的端到端(E2E)响应延迟大约在
1.8 秒至 2.6 秒之间。
这个耗时完全在日常工作可承受的正常范围内。如果你希望将延迟进一步压缩至 1 秒以内,唯一的办法是将 Notion 中的笔记定期冷同步到本地 NAS 的 PostgreSQL(利用 pgvector),用本地局域网的向量库查询代替跨国 API 的 Notion 检索。
n8n vs 自研 Python 脚本:知识库智能体选型对比
如果只是做个人知识库问答,n8n 的价值在于把 Notion、模型、错误流和通知节点快速串起来;如果你要做企业级高并发检索,自研 Python 脚本会给你更强的索引、缓存和权限控制能力。
| 对比维度 | n8n 工作流方案 | 自研 Python 脚本方案 | 推荐选择 |
|---|---|---|---|
| 上手速度 | 通过可视化节点连接 Notion、OpenAI、Switch 和 Error Workflow,半天内可跑通 MVP | 需要自行编写 Notion 拉取、切片、向量化、API 服务和前端入口 | 个人和小团队优先 n8n |
| 运维复杂度 | Docker 自托管后主要维护凭证、节点版本和执行日志 | 需要维护依赖、队列、数据库迁移、日志、权限和部署流水线 | 有工程团队再选 Python |
| 检索质量 | 适合低频、低文档量、基于 Notion Search 的关键词检索 | 可接入 pgvector、Milvus、rerank、混合检索和本地缓存 | 大规模知识库优先 Python |
| 成本控制 | 通过 Top K、Window Memory 和 Error Workflow 控制 Token 与失败重试 | 可做更细粒度的批处理、缓存命中、模型路由和请求合并 | 高调用量优先 Python |
| 权限治理 | 依赖 Notion Integration 最小授权和 n8n 凭证管理 | 可按用户、空间、文档、字段实现更细粒度权限矩阵 | 企业权限复杂时选 Python |
| 适用场景 | 个人第二大脑、团队 Wiki 助手、低代码内部工具 | 多租户知识库、客服知识中台、合规审计系统 | 按规模与合规要求选择 |
第六关:常见坑与生产环境报错 (Error Logs)
报错一:Notion API Rate Limit 429 报错
Error: Request failed with status code 429
{
"object": "error",
"status": 429,
"code": "rate_limited",
"message": "You have been rate limited. Please try again later."
}- 病因:Notion 官方对集成 API 限制为每秒最多 3 次请求。如果你的 n8n 实例开启了高频轮询,或者多租户并发访问,瞬间就会触发限流。
- 解决对策:在 n8n 的 Notion 节点 Settings 里开启 Retry On Fail,最大重试次数设为 3,延迟设为 5000 毫秒,利用被动等待退让策略平滑躲过请求峰值。
报错二:Notion API Token 401 权限报错
Error: Request failed with status code 401
{
"object": "error",
"status": 401,
"code": "unauthorized",
"message": "API key is invalid or permissions are incorrect."
}- 病因:API 令牌拼写错误,或者关联的 Integration 被工作区管理员中途删除、甚至没有将对应的 Page 或 Database 分享给该 Integration。
- 解决对策:重新登录 Notion 后台,核对 Token 指纹是否一致。特别检查目标父级页面是否在 Connection 菜单中正确添加了该连接,确保物理授权管道畅通。
报错三:Timeout Error 节点超时报错
NodeApiError: [TimeoutError] The request to Notion API timed out after 30000ms.- 解决对策:自托管环境下,检查你的 VPS 或是本地 NAS 的代理配置是否失效。在 n8n node 设置中,强行将超时阈值拉大至 60 秒,并在此节点后面挂载 Switch 做 Fallback 兜底,防止超时导致整个 AI 流程雪崩。
