n8n Queue Mode + Redis 实战:什么时候需要把工作流拆到队列里?
这篇文章记录了我在贵阳实验室的实战过程。我坚信,在技术下行的时代,程序员唯一的护城河就是通过 AI 建立属于自己的数字资产。
本文解决的问题
- 解决了单机部署 n8n 时,因高并发 Webhook 回调涌入和慢速 AI 节点执行而导致主线程被死死卡住的前端无响应难题。
- 解决了在多容器运行环境下,不同执行阶段生成的本地临时文件因物理隔离而频繁报错 FileNotFound 的共享存储痛点。
- 提供了从小规模到 Webhook 高峰期等三种生产级别的分布式拓扑架构设计,并给出了具体的并发控制与 API 速率限制配置。
适合谁读
- 已经使用 Docker 部署了自托管 n8n、但随着业务规模扩大经常遇到后台莫名 OOM 崩溃的独立开发者。
- 正在设计企业级 AI 自动化工作流集群,需要对任务进行队列管理和并发控制的后端与运维工程师。
- 熱衷于利用低代码与大模型进行业务提效,想为自己的个人 IP 打造一套坚不可摧的底层计算引擎的极客。
一、为什么单机 n8n 后面会变慢?
单进程架构是单机版 n8n 在并发和耗时任务面前的物理死穴。作为一个小白全栈,我刚开始折腾 AI 工作流的时候,觉得单容器部署(Regular Mode)简直完美。我在本地的 Mac mini 上几分钟就拉起了一个服务,把各种轻量级的自动化任务(比如定时抓取网页、同步 GitHub 提交、发送邮件通知)跑得顺顺当当。
然而,一旦你把工作流的复杂度提上来,加入了一堆外部 API 和大模型计算,系统就会开始显现出严重的疲态:
第一,Webhook 请求变多。当你在外网挂载了各种服务回调,一旦赶上某天流量暴增,几十个 Webhook 同时砸过来。在默认单进程模式下,n8n 既要解析这些网络请求,又要为每个请求初始化一个工作流运行实例,Node.js 极薄的单线程事件循环会在瞬间被这些微任务塞满。
第二,AI 节点调用时间变长。大模型的 API 响应从来都不是以毫秒计的。一个包含多步推理、提示词优化和长文本摘要的 AI 节点,执行一次可能需要三十秒到数分钟。如果同时有五个这样的任务在跑,单机 n8n 的主线程就会陷入长时间的同步等待,无法腾出手来处理其他轻量级工作流。
第三,外部 API(如 Google Sheets、Gmail、Slack)开始变慢并触发频率限制。由于没有统一的队列排队和并发控制,所有执行任务都是野蛮生长,经常会因为瞬间发出大量并发 HTTP 请求而被外部 API 封禁或强制拒绝服务。
第四,长任务阻塞短任务。比如一个需要运行十分钟的批量文件处理任务在后台跑着,这时候刚好有一个需要在一秒钟内做出响应的 Webhook 进来了,但它只能在事件队列里眼巴巴排队,直到主线程有空。这直接导致 Webhook 接收超时,触发外部发送方的重试。
第五,失败重试导致任务堆积。在没有队列机制的情况下,一旦大面积调用 LLM 因超时而触发工作流重试,这些重试任务会和新进来的任务混在一起,直接把原本就已经满负荷运转的 Node.js 堆内存(V8 默认仅有 1.4GB 左右限制)彻底撑爆,整个容器直接崩掉重启。
n8n 不是不能跑,而是接收任务和执行任务都压在一个实例上时,迟早会互相影响。我们需要将前台接待和后台炒菜进行物理分离。
二、Queue Mode 解决什么问题?
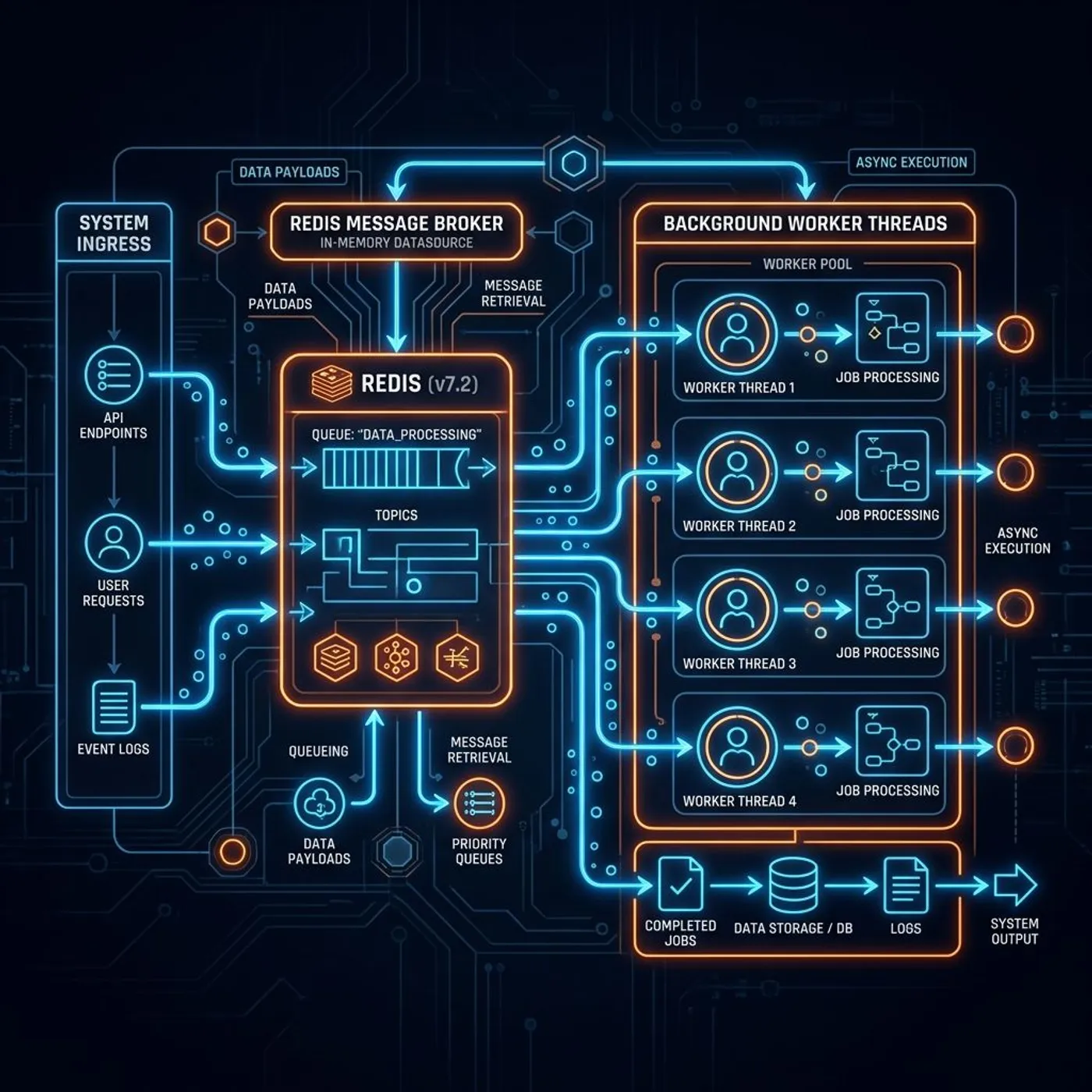
队列模式通过引入消息中间件,将 n8n 的系统架构从单进程升级为分布式微服务。
在 Regular Mode(默认模式)下,整个 n8n 容器是一个大锅饭,一个实例同时负责接收 Webhook、展示 Web低代码 UI、调度任务节点以及执行具体的脚本代码。只要其中任何一环因为 CPU 爆满或内存泄漏倒下,整个系统的所有功能都会瞬间瘫痪。
在 Queue Mode(队列模式)下,主节点解耦为只读/轻量级服务,具体的执行任务交给了底层的 Workers。
具体的分工架构如下:
- Main 实例:作为系统的唯一控制中心,仅负责向用户展示前端画布、保存工作流定义、接收外部 Webhook。它收到任务后,自己不动手执行,而是将任务参数打包发往 Redis。
- Redis 组件:作为内存级的消息中间件,维护待处理的任务队列,负责在 Main 实例和各个 Worker 之间进行消息分发与状态同步。
- Worker 实例:专门的后台计算进程。它们不暴露任何外部 HTTP 端口,只通过 TCP 持续监听 Redis 队列,拉取任务进行本地计算。
- Database (PostgreSQL):存储系统的核心持久化数据,如用户凭证、工作流元数据以及最终的执行历史记录。
通过这种方式,系统的吞吐量不再受限于单个 Node.js 进程的事件循环。Main 节点能够以几毫秒的速度吞下成千上万的并发 Webhook,而具体的计算任务则在 Redis 队列中排队,由下方的 Workers 慢慢消化。即使后台的某个 Worker 因为跑超大文本导致 OOM 重启,Main 节点的前端控制台也依然丝滑,不会受到任何波及。
三、什么时候需要 Queue Mode?
引入队列模式是一次架构层面的升级,会带来额外的部署成本和服务器资源开销。因此,我们必须有一套清晰的物理指标来判定升级时机:
首先,当你发现外部的 Webhook 请求经常出现 504 Gateway Timeout 或 499 客户端主动断开时。这说明主进程由于在同一时间忙于处理已经拉起的工作流,已经无暇顾及新的 HTTP 连接握手,必须将接收与执行解耦。
其次,当你的工作流中 AI 调用或慢速计算节点的执行时间经常超过三十秒甚至数分钟时。这种慢速任务在 Regular 模式下是事件循环的毒药,一旦并发,就会让短平快的普通自动化任务产生明显的排队延迟。
再者,当你的日常并发 Workflow 数量明显增多,每天的执行历史记录(Executions)突破一万次大关时。
另外,任务失败重试造成严重的雪崩堆积。比如由于网络波动,突然有上百个调用 LLM 的任务出错并自动触发了三分钟后重试,这些重试任务如果在同一时间点被塞回单机主线程,会瞬间造成第二次系统死锁。
最后,当你想通过增加服务器或增加 Worker 进程来线性扩展系统的执行能力,或者你需要极其清楚地控制每个工作流节点的并发数限制时。这是常规单进程模式无法给你的物理保障。
四、Redis 在 n8n Queue Mode 里负责什么?
很多人在刚接触 n8n 队列模式时,会把 Redis 的作用和 PostgreSQL 数据库混淆。
我们需要明确一个物理常识:Redis 不是保存你的业务数据,而是帮助 n8n 协调待执行任务和 worker。
在具体运作流程中,Redis 扮演着数据传送带的角色:
- 当 Main 实例监听到触发器(比如一个定时 Cron 或 Webhook 传入)时,它会生成一个代表本次运行的作业(Job),并写入 Redis 的 Bull 队列中。
- 正在监听 Redis 的多个 Worker 实例会通过竞争消费者模式,由其中一个闲置的 Worker 将该 Job 从队列中捞走,并在自己的容器进程里运行它。
- 执行过程中,Worker 会将当前运行的节点状态、中间变量和输出结果通过 Redis 频繁地和 Main 实例同步,以便我们在前端控制台上能实时看到那条绿色的「执行成功」路径。
- 所有的工作流配置、历史凭证、已经彻底完成的执行记录(Succeeded/Failed)等需要长久保存的物理数据,依然会最终写入 PostgreSQL 或 MySQL 关系型数据库。Redis 里的队列数据在任务完成后会被自动清理,保持极高的吞吐率。
因此,如果 Redis 意外挂掉,n8n 的 Web 界面依然可以通过读取 PostgreSQL 正常访问,历史数据也不会丢失,但所有工作流的分发和后台执行会被立即卡死。
五、Worker 应该怎么拆?
根据团队规模和业务流量的变化,Worker 应该采用不同的分布式拆分拓扑:
1. 小规模模式(适合个人及极小团队起步)
拓扑结构:1 main + 1 Redis + 1 worker + 1 database
在单台高性能 VPS 或 NAS 上运行。Main 节点、Worker 节点和 Redis、Postgres 运行在同一个 Docker 虚拟网络中。这可以提供内存层面的物理隔离,防止执行崩溃波及前端 Web 界面。
2. 中等规模模式(适合有稳定流量的业务)
拓扑结构:1 main + 1 Redis + 2-3 workers + 1 database
将 Worker 实例进行水平扩展。比如在 docker-compose 中启动三个相同的 Worker 容器,或者将这三个 Worker 部署在不同的物理服务器上,通过内网 TCP 共同连接到云端的 Postgres 和 Redis 上。这能提供优秀的故障冗余,任何一个 Worker 宕机,剩余的 Worker 会自动接管队列中的剩余任务。
3. Webhook 高峰模式(企业级高并发架构)
拓扑结构:webhook instance + main instance + Redis + 多 worker + database
在超高并发 Webhook 回调场景下,n8n 允许我们将 Main 实例进一步拆分为专门接收 Webhook 的独立实例(Webhook Instance)和专门提供控制台 UI 的 Main 实例。Webhook 节点只负责做极简的安全验证和队列写入,完全不承载任何管理逻辑,配合多 Worker,能顶住秒级几千次的并发冲击。
以下是适用于中等规模模式的完整 docker-compose.yml 部署示例,它清晰地展示了 Main、Worker、Redis 与 Postgres 的解耦编排:
version: '3.8'
services:
n8n-postgres:
image: postgres:16-alpine
container_name: n8n-postgres
environment:
- POSTGRES_USER=n8n_db_user
- POSTGRES_PASSWORD=n8n_secure_pass_998
- POSTGRES_DB=n8n_production
volumes:
- pg_data_volume:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U n8n_db_user -d n8n_production"]
interval: 5s
timeout: 5s
retries: 5
restart: always
n8n-redis:
image: redis:7.2-alpine
container_name: n8n-redis
command: redis-server --appendonly yes
volumes:
- redis_data_volume:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 5
restart: always
n8n-main:
image: docker.n8n.io/n8nio/n8n:latest
container_name: n8n-main
depends_on:
n8n-postgres:
condition: service_healthy
n8n-redis:
condition: service_healthy
ports:
- "5678:5678"
environment:
- N8N_HOST=localhost
- N8N_PORT=5678
- N8N_PROTOCOL=http
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=n8n-postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n_production
- DB_POSTGRESDB_USER=n8n_db_user
- DB_POSTGRESDB_PASSWORD=n8n_secure_pass_998
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=n8n-redis
- QUEUE_BULL_REDIS_PORT=6379
- N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
volumes:
- shared_files_volume:/home/node/.n8n
restart: always
n8n-worker-1:
image: docker.n8n.io/n8nio/n8n:latest
container_name: n8n-worker-1
depends_on:
n8n-postgres:
condition: service_healthy
n8n-redis:
condition: service_healthy
command: worker --concurrency=5
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=n8n-postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n_production
- DB_POSTGRESDB_USER=n8n_db_user
- DB_POSTGRESDB_PASSWORD=n8n_secure_pass_998
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=n8n-redis
- QUEUE_BULL_REDIS_PORT=6379
- N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
volumes:
- shared_files_volume:/home/node/.n8n
restart: always
n8n-worker-2:
image: docker.n8n.io/n8nio/n8n:latest
container_name: n8n-worker-2
depends_on:
n8n-postgres:
condition: service_healthy
n8n-redis:
condition: service_healthy
command: worker --concurrency=5
environment:
- DB_TYPE=postgresdb
- DB_POSTGRESDB_HOST=n8n-postgres
- DB_POSTGRESDB_PORT=5432
- DB_POSTGRESDB_DATABASE=n8n_production
- DB_POSTGRESDB_USER=n8n_db_user
- DB_POSTGRESDB_PASSWORD=n8n_secure_pass_998
- EXECUTIONS_MODE=queue
- QUEUE_BULL_REDIS_HOST=n8n-redis
- QUEUE_BULL_REDIS_PORT=6379
- N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
volumes:
- shared_files_volume:/home/node/.n8n
restart: always
volumes:
pg_data_volume:
redis_data_volume:
shared_files_volume:六、并发怎么控制?
队列模式赋予了我们精准控制并发的能力,但许多开发者在切换后往往陷入了「Worker 越多越好」的盲目扩张误区。
在 Queue Mode 下,我们主要通过在 Worker 启动命令中传入 —concurrency 参数来控制每个 Worker 可并行运行的作业数量(例如上面配置中的 command: worker —concurrency=5)。如果不指定,默认值通常为 10。
这意味着两个 Worker 最多会并行消费 10 个队列任务。如果新进来了第 11 个任务,它会在 Redis 队列中静静排队,直到有空闲的 Worker 空出槽位。这套并发限制机制与 Regular Mode 仅依赖物理内存撑上限的野蛮规则完全不同,它在物理上是可控的。
为了防止队列系统成为下游基础设施的压力传染源,我们在进行并发设计时必须遵循以下克制原则:
第一,不要无限增加 Worker 容器。增加 Worker 意味着它们会与 PostgreSQL 数据库和 Redis 建立更多的物理 TCP 连接。如果数据库的 max_connections 限制过低,或者 Redis 本身没有做好持久化优化,Worker 节点会频繁掉线并报错。
第二,不要无限提高 concurrency 并发数。虽然调大 concurrency 可以缩短轻量任务的排队时间,但如果你的工作流中包含复杂的 AI 计算,高并发会导致你的 LLM Token 成本瞬间失控,甚至由于瞬间请求过于频繁,直接触发 OpenAI 或 Anthropic 的 API Rate Limit 限流机制,导致任务大面积重试失败。
我们需要根据服务器的 CPU 核心数、可用物理内存、下游数据库的连接上限以及外部 AI 服务商的速率限制,科学计算出一个保守的并发安全值。
七、AI 工作流为什么更适合考虑队列?
相比于传统的轻量级 API 对接,AI 自动化工作流的特性决定了它与任务队列是天然的物理伴侣。
主要有以下物理原因:
首先,LLM 调用耗时极不稳定。同一个提示词,在模型服务商服务器拥堵时,响应时间可能会从两秒拉长到一分钟。这种高度的不确定性如果在单机版 n8n 中并发发生,会直接卡死主线程的事件轮询。
其次,外部模型 API 存在严格的频次限流。如果没有任何队列缓冲区,一旦你的工作流需要批量处理五百条客户反馈,n8n 会在秒级时间内向模型接口发出五百次请求,这会瞬间触发 Rate Limit 错误。利用队列并设置合理的 Concurrency,你可以让任务像流水线一样匀速发送,避免接口报错。
再者,长文本处理极易超时。例如,自动提取音视频并使用大模型进行全文翻译和摘要整理,这类超长任务一旦多任务并发,单台服务器的 CPU 和内存占用会瞬间触顶。
另外,多个 AI 工作流同时执行时的 Token 消费成本是惊人的。如果缺乏队列排队机制,一旦系统出现大面积并发执行,你的信用卡额度可能会在几分钟内被超高并发的无效重试刷爆。
AI 工作流不是每次都慢,但它的不确定性更高,所以更需要队列和并发控制。
八、个人开发者什么时候不需要 Queue Mode?
在决定折腾队列模式之前,小白开发者应该先做一次物理降温,评估一下自己是不是在做过度设计。
如果你符合以下特征,请立刻放弃 Queue Mode:
第一,你一天的执行量只有几十次或几百次,即使偶有排队也不会影响业务。 第二,你的工作流几乎没有使用高并发 Webhook 接收外部未知用户的请求,主要是依靠定时 Cron 触发或者自己在后台手动点击执行。 第三,你的服务器资源极其有限,VPS 只有 1 核 1GB 内存。这种配置下强行塞入 Postgres、Redis、Main 容器和 Worker 容器,会导致系统由于物理内存不足直接频繁死机。 第四,你的工作流并没有面对真实用户,只是作为自己日常提效、抓取个人资料或管理看板的小助理,即使偶尔因为网络问题超时,也完全可以接受手动重试。
Queue Mode 是扩展方案,不是起步方案。在业务起步阶段,用好 Regular 模式,把有限的精力放在设计优秀的工作流逻辑上,才是性价比最高的产品迭代路径。
九、常见错误
常见错误 1:没有流量就先上 Queue Mode
许多开发者在项目连一个真实用户都没有的时候,就开始构建高可用的 Redis 队列和多 Worker 集群。这不仅浪费了服务器物理算力,还极大地增加了日后的升级和排障成本。当工作流出错时,你需要在 Main 容器、Redis 容器、多个 Worker 容器以及数据库日志之间反复跳转,排障效率极其低下。
常见错误 2:把 Redis 当数据库
Redis 在队列模式下仅仅作为 Bull 消息引擎的临时存储介质。有些人在配置工作流时,试图用 Redis 的数据卷持久化来替代 PostgreSQL 存储工作流定义或凭证。必须明确,Redis 里的队列数据在完成消费后会被自动清除,它绝不能替代 Postgres 或 MySQL 来保存任何核心资产数据。
常见错误 3:Worker 开得太多
盲目开启过多的 Worker 容器不仅会把主服务器的物理内存耗尽,还极易把读写压力全部转移到后端的 PostgreSQL 数据库上,造成数据库连接池爆满。同时,这也可能瞬间拉垮外部的大模型 API 接口,引发更难排查的 API 速率限制错误。
常见错误 4:不控制 AI 节点成本
引入队列模式虽然极大地提升了系统的并发执行能力,但也意味着当出现死循环工作流或大面积重试时,系统能够以惊人的速度消耗你的 AI 账号余额。如果不加限制地并发运行调用高级模型的节点,短时间内会产生高昂的 Token 账单。
常见错误 5:Webhook、worker、main 职责混乱
在队列部署环境下,如果依然在 Worker 实例上映射了 5678 的外部公网端口,或者让 Main 节点也参与工作流的后台运算,就会导致各容器之间的职责错乱,无法发挥队列模式应有的流量隔离效果。
十、上线检查清单
- 是否真的出现了执行堆积或超时?
- 是否已经有稳定数据库?
- Redis 是否单独部署并持久化配置合理?
- main instance 和 worker 是否职责清楚?
- worker concurrency 是否有限制?
- AI API 是否有 rate limit 和成本控制?
- Webhook 是否有超时和重试策略?
- 是否能查看失败任务和重试记录?
- 是否有日志和监控?
- 是否有回滚到 regular mode 的方案?
FAQ
n8n Queue Mode 一定需要 Redis 吗?
是,Queue Mode 必须依赖 Redis。n8n 底层基于 Bull 引擎来做任务的队列分发与调度,而 Bull 的所有核心数据结构和通信队列都是基于 Redis 内存存储实现的。因此没有 Redis,队列模式将完全无法运转。
个人开发者要不要一开始就用 Queue Mode?
不建议。早期 Regular 模式部署极其简单,几乎没有心智负担。建议等业务量上升,在后台 Execution 列表中频繁观察到执行堆积、外部 Webhook 经常发生 504 超时、或者慢速 AI 任务耗时明显增加拖垮前端 UI 时,再考虑引入 Redis 进行 Queue Mode 升级。
Queue Mode 能解决所有性能问题吗?
不能。队列模式只能帮助你拆分执行主进程的事件循环压力,实现高吞吐的任务排队。如果你的工作流设计存在死循环、PostgreSQL 数据库没有做索引优化、外部 API 经常封禁你、或者 LLM 接口频繁限流,这些底层物理瓶颈依然存在,需要进行针对性的逻辑重构。
Worker 越多越好吗?
不是。Worker 数量的增加会呈线性增加与 Redis 和关系型数据库的 TCP 连接数。如果超出物理数据库的连接槽限制,会导致整个集群雪崩。同时,过多的 Worker 并发消费可能会让外部大模型 API 直接抛出 Rate Limit 错误,需要合理配置并发控制限制。
AI 工作流为什么更需要队列?
因为大模型 API 的调用耗时具有极高的波动性,且单次调用成本高、频次限制严格。队列能让这些不稳定、高成本的任务在后台以安全、匀速的节奏排队消费,并提供完备的失败重试防护,确保系统的高确定性。
