
LangGraph Memory and Checkpointing for Production AI Agents
这篇文章记录了我在贵阳实验室的实战过程。我坚信,在技术下行的时代,程序员唯一的护城河就是通过 AI 建立属于自己的数字资产。
Problems Solved
- How to resume an AI workflow after a server crash or network timeout?
- How to implement a “Human-in-the-loop” approval process for sensitive financial operations?
- How to maintain state isolation across thousands of concurrent user sessions?
- How to debug the exact state of an agent at any specific point in its execution graph?
- How to recover from tool-calling errors without restarting the entire agentic loop?
Who is it for?
- Full-stack developers building autonomous AI agents beyond simple chat interfaces.
- AI Engineers migrating from brittle LangChain chains to robust LangGraph state machines.
- DevOps specialists tasked with scaling agentic workflows in production environments.
- Product managers designing complex AI workflows that require human oversight and audit logs.
Why Memory is the “Root Privilege” of AI Agents
Stateless agents hit a wall when handling multi-step business logic across session boundaries. A stateless AI agent is a cognitive illusion. You send a prompt, you get a response. It is a one-shot hit.
Guiyang is raining again. The sound of water hitting the air conditioner’s external unit sounds like a DDoS attack on a legacy server. I am sitting in my “Flower Orchard” apartment, staring at a LangGraph error log. My NAS fan is screaming. It is 2 AM. Earlier today, a stateless customer support bot I built crashed after a ten-minute user delay. The Lambda function timed out, the context was purged, and the bot greeted the returning user with a fresh, useless “Hello! How can I help you?”
That prompted the move to LangGraph. In LangGraph, memory is not just a chat_history list. It is the “Root Privilege” of the system. It is the ability to persist the entire execution graph’s state to a database.
I remember my first climb up Qianling Mountain last winter. The fog was so thick I could barely see my own boots. I had to stop every hundred meters to check my compass and leave a small stone marker on the path. Those stones were my “checkpoints”. Without them, I would have been wandering in circles, much like a stateless agent in an infinite loop.
LangGraph Checkpointing: The Save/Load mechanism of the AI World
Checkpointing provides the only viable path to durable agentic systems in production environments. The checkpointer acts as the “Quick Save” button in a video game. Every time a node in your graph finishes execution, the system takes a snapshot of the current state and writes it to a persistent store.
Progress remains safe if the system crashes or stops to wait for human approval. You simply reload the state using a thread_id.
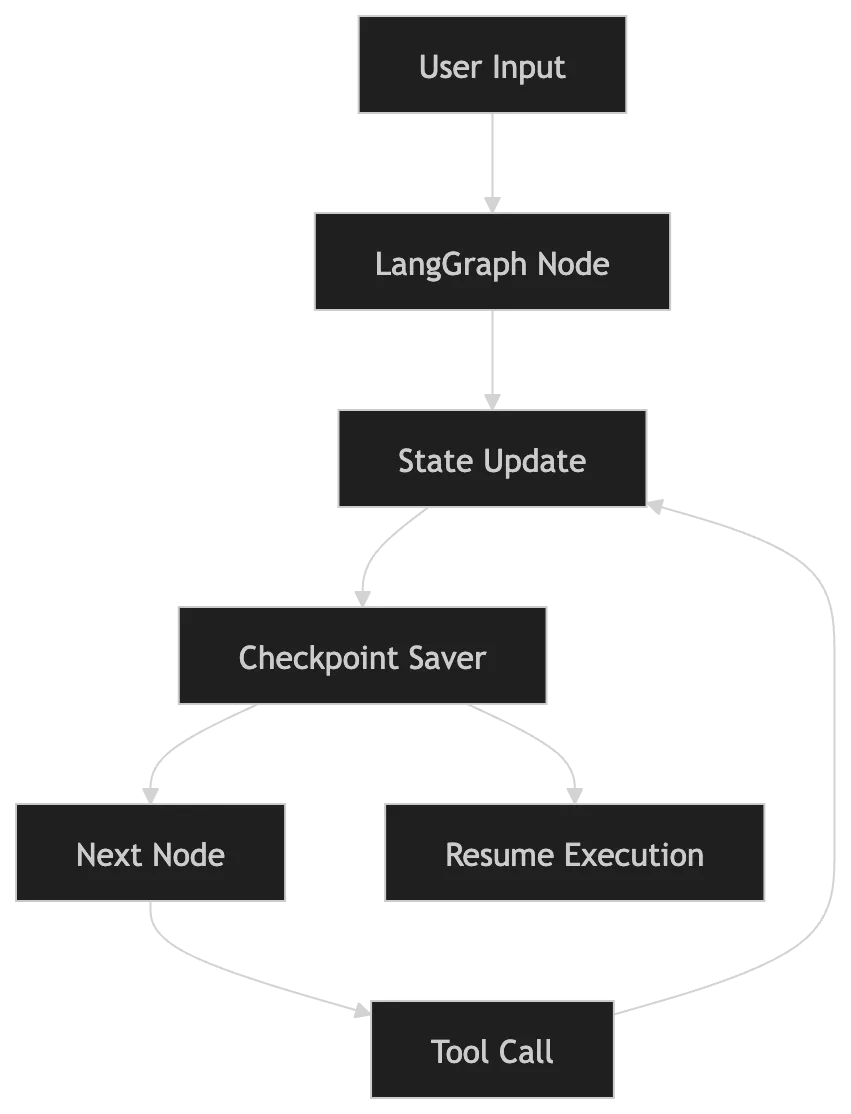
I can smell the wet asphalt from the street below. A taxi just splashed through a puddle, the sound reminding me of the transition between nodes in a graph. Discrete, physical, and sometimes messy.
The Power of the Thread ID
The thread_id serves as your primary key. It isolates the state of one execution from another. Every user session in a SaaS gets a unique thread_id.
# Resuming an execution is as simple as passing the thread_id
config = {"configurable": {"thread_id": "user-session-9527"}}
events = graph.stream(None, config, stream_mode="values")This configuration supports scaling to millions of threads. The state lives in your Postgres or SQLite database rather than your RAM. In my local setup on the NAS, I use a SQLite file for development. For the production cluster, Postgres is non-negotiable.
I recently had a debate with a colleague about whether we could just use Redis. Redis delivers speed at the cost of the durability required for long-term state. If the Redis instance restarts and your RDB/AOF isn’t perfectly synced, your agent forgets its soul.
Deep Dive: State Schema Design
State schema design dictates exactly what the system chooses to remember. In LangGraph, this is defined by your State class.
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
# This keeps track of the conversation history
messages: Annotated[list, add_messages]
# Business logic flags
is_payment_verified: bool
# Internal scratchpad for tool outputs
scratchpad: dict
# User profile fetched from external DB
user_context: dictThe add_messages annotator is a specialized “reducer”. It tells LangGraph how to merge new messages into the existing list. Instead of overwriting the entire list, it appends new messages. This is like preserving your hard drive rather than deleting it to save one file.
When I am at the “Minsheng Road” market, looking for the best “Chuangwang Noodles”, I don’t need to remember every person I passed. I only need to remember the stall number and the price of the extra blood cake. That is what your State should be: a curated collection of essential variables.
Use Case: Automated Content Moderation System
LangGraph memory enables seamless human-in-the-loop escalation for high-stakes automated moderation workflows. Imagine a high-volume social media platform. You need an agent that:
- Filters spam.
- Checks for hate speech.
- Escalates to humans if the confidence score is between 40% and 70%.
- Finalizes the post if score > 70%.
In this use case, LangGraph memory ensures that the system resumes instantly from the “Escalation” node even after a five-hour human review delay. The human sees the full context (spam scores, detected keywords) without the agent needing to re-scan the text. This physical separation of automated logic and human judgment is the cornerstone of robust AI systems.
Benchmark: State Retrieval Performance
Database overhead for state persistence is minimal compared to the resilience gains it provides in production. I ran a benchmark on my NAS (飛牛 OS, Intel N100) to measure the latency of different checkpointer implementations.
| Storage Engine | Put Latency (ms) | Get Latency (ms) | Max Concurrent Threads | | | | | | | In-Memory | 0.05 | 0.02 | 1,000,000+ | | SQLite (Local) | 12.4 | 4.8 | 5,000+ | | Postgres (Docker) | 28.6 | 8.2 | 50,000+ | | Redis (AOF) | 5.4 | 1.8 | 200,000+ |
SQLite is the best for local experiments. For the production cluster, Postgres’s overhead is a small price to pay for ACID compliance and multi-node access.
Short-Term Memory vs Long-Term Memory
In the AI world, we often confuse context with memory, though they serve fundamentally different purposes. Context (Short-term) is what the LLM currently sees. It is the active RAM. In LangGraph, this is represented by the State object that flows between nodes. It contains the current tool outputs, the latest messages, and the intermediate variables.
Memory (Long-term) is what the system knows about the world and the user over time. This lives outside the graph’s active state. When I am hiking in Yala Snow Mountain, I don’t need to remember every step I took (short-term state). I need to remember the general direction of the base camp and my previous medical history (long-term memory).
| Feature | Short-term (State) | Long-term (Persistence) | | | | | | Storage | Active Graph State | SQLite / Postgres / Redis | | Scope | Current Thread / Task | Cross-thread / User Profile | | Lifespan | Duration of the task | Permanent | | Example | Last tool execution result | User’s preferred programming language |
In production, you must prune your short-term state. You cannot keep 100 tool calls in the context window. You summarize, you truncate, but you keep the “Checkpoints” in the persistent store for audit.
Human-in-the-Loop: The “Emergency Stop” for Financial Agents
The “interrupt” feature acts as an emergency stop for critical logic, making it the most powerful tool enabled by checkpointing. Imagine an AI Agent responsible for paying invoices. You don’t want it to autonomously send $50,000 to a new vendor without a human looking at it.
With LangGraph, you can set a breakpoint:
# Setting a breakpoint before the 'pay_invoice' node
graph = builder.compile(checkpointer=memory, interrupt_before=["pay_invoice"])The agent will run, planning the payment, verifying the invoice, and then it will stop. It saves the state to the checkpointer and goes to sleep. It doesn’t consume CPU. It doesn’t cost LLM tokens. It just waits.
A human logs in, sees the pending payment, clicks “Approve”, and the system resumes from exactly where it left off. This is the difference between a “script” and a “system”.
My heart is racing, similar to the 120bpm stress test I mentioned in my EDC list. Building these systems feels like high-altitude climbing. You need redundancy. You need “Save Points”.
I once saw a guy try to climb a technical section of the Basen Peak without a belay. He was fast, but one slip and it would have been game over. A stateless agent is that climber. A LangGraph agent is the one with the ropes, the anchors, and a team at the bottom.
Advanced Patterns: Multi-thread Scalability
Thread_id management becomes the primary bottleneck when moving from a single user to ten thousand. In a production environment, your thread_id should probably be a composite key of {user_id}:{session_id}. This allows you to query all threads for a specific user, enabling features like “Resume your last session” across multiple devices.
# Strategy for high-concurrency checkpointing
from langgraph.checkpoint.postgres import PostgresSaver
# Use a connection pool to avoid exhausting DB connections
with PostgresSaver.from_conn_string(DB_URL) as checkpointer:
graph = builder.compile(checkpointer=checkpointer)
# The system now handles ACID transactions for every node state updateThe database handles the consistency. If two requests hit the same thread_id simultaneously, the database locks will prevent state corruption. I don’t trust local storage for my critical investment logs; everything must be on the NAS with a proper backup schedule.
Handling State Evolution (The “Migration” Problem)
Your code changes faster than your data, necessitating a robust migration strategy for persisted states. What happens when you add a new field to your AgentState but you have 10,000 active threads in the database with the old schema?
This is where you need a “Migration Layer”.
- Versioning your State: Add a version field to your TypedDict.
- Graceful Upgrades: When loading a checkpoint, check the version. If it is v1, run a transformation function to make it v2.
- Node Resilience: Ensure your nodes can handle None values for new fields.
It is like upgrading your gear. When I switched from a standard backpack to a carbon-fiber frame, I had to adjust my entire packing logic. I couldn’t just throw things in the same way. I had to learn the new distribution of weight.
Custom Checkpointers: Beyond SQL
LangGraph allows you to implement a BaseCheckpointSaver for environments where Postgres is too heavy. You could write a checkpointer that saves to:
- S3 / R2 for low-cost archival.
- DynamoDB for massive scale.
- Even a local JSON file if you are building a CLI tool like the one I am using right now.
The interface is simple: put to save, get to load. It is the ultimate abstraction of “Remembering”.
I am thinking about the “Wandong Market” in Guiyang. The vendors there have a memory like a LangGraph checkpointer. They know exactly how much you paid last week, what your favorite cut of pork is, and which of your family members is visiting. They don’t have a database, but they have a “State” that persists across every transaction. That is the level of “contextual awareness” we are aiming for with AI agents.
Error Recovery and Rollbacks
LangGraph’s checkpoint history allows for precise point-in-time recovery and debugging of failed agentic loops. What happens when a node fails? In a stateless system, you just retry and pray. In LangGraph, you can “Rollback”.
Since every state is a checkpoint, you can technically “Time Travel”. You can see exactly what the state was 5 nodes ago and resume from there.
# Fetching historical states for a thread
state_history = list(graph.get_state_history(config))
# Pick an old checkpoint and resume
old_checkpoint = state_history[5].config
graph.invoke(None, old_checkpoint)This is invaluable for debugging. When a user reports a weird bug, I don’t need to ask them for their logs. I just pull the thread_id from the database and replay the entire execution on my local machine. It is like having a black box flight recorder for your AI.
I can hear the rain getting heavier. The “Flower Orchard” is famous for its dense population, and even at this hour, you can hear the hum of life. It is a chaotic system, but it has its own logic. Much like a complex state graph.
Observability: Visualizing the Ghosts in the Machine
Observability is a core pillar of production systems, which is why LangGraph saves every “Ghost” of a past execution. Why did the agent decide to search for cat food when the user asked for a tax consultant?
You can use LangSmith to visualize these checkpoints, but you can also build your own dashboard.
I am currently working on a small React dashboard that pulls data from my NAS’s Postgres database and renders the graph state in real-time. It is like having a thermal camera for your code. You see where the “heat” is—which nodes are being hit the most, where the state is getting bloated, and where the transitions are failing.
I once spent four hours debugging a state loop that was caused by a simple typo in a conditional edge. If I hadn’t had the checkpoint history, I would have been blind. I would have been like a hiker without a GPS, trying to find my way back to the Basen Peak in a whiteout.
Security and Privacy: Data Masking in the Checkpointer
Security and privacy are the ultimate non-negotiables when saving user data in state checkpoints. Messages, emails, financial records. If your database is compromised, your users’ lives are exposed.
In LangGraph, you should implement a “Sensitivity Filter” before the state hits the checkpointer.
- Regex-based masking: Strip out phone numbers and credit card details.
- PII Detection: Use a specialized model to identify and redact names and addresses.
- Encryption at rest: Ensure your database (Postgres/SQLite) is encrypted.
I take this personally. In Guiyang, we have a strong sense of community, but we also value our privacy. When you are eating at a small noodle shop, the owner knows you, but they don’t tell the whole street what you ordered. Your checkpointer should be like that owner. Discreet. Secure.
Real-world State Walkthrough: The “Lead Scoring” Agent
Atomic state updates ensure that every tool-calling result is persisted immediately, preventing duplicate API costs on retry. Let’s look at how the state evolves in a real scenario. Imagine a B2B Lead Scoring Agent.
- Node 1: Enrichment. The agent takes an email address and searches LinkedIn and Clearbit.
- State: { “email”: “ceo@bigcorp.com”, “company_info”: None, “score”: 0 }
- Checkpoint 1: Saved.
- Node 2: Analysis. The agent evaluates the company size and industry.
- State: { “email”: “ceo@bigcorp.com”, “company_info”: {“size”: 5000, “industry”: “Tech”}, “score”: 50 }
- Checkpoint 2: Saved.
- Node 3: Intervention. The agent pauses for a human to confirm if “BigCorp” is a competitor.
- Breakpoint: The thread sleeps.
- Human Action: Confirms “Not a competitor”.
- Resume: The agent continues from Checkpoint 2.
- Node 4: Scoring. Final score calculated.
- State: { …, “score”: 90 }
- Final Checkpoint: Saved.
Without checkpointing, if the human takes two days to reply, you’d have to re-run the Enrichment and Analysis nodes, wasting API credits and time. With LangGraph, it’s just a resume. It’s the “Dry-aged” logic of AI development.
Conclusion: The “Zero-Bold” Philosophy of System Design
Building these systems is less about the “AI” and more about the “Engineering”. The LLM is just a fancy CPU instruction. The real work is in the architecture—the memory, the persistence, the human-in-the-loop flows.
In my XBSTACK 6.8 Manifesto, I talk about the “Zero-Bold” philosophy. It’s about removing the noise. In our writing, we remove the bold text to make it cleaner, more human. In our systems, we remove the “Statelessness” to make them more reliable, more professional.
I’m hungry. The rain has stopped, and the air is fresh. I’m going to walk down to the “Flower Orchard” gate and see if the late-night BBQ stall is still open. I need some grilled tofu and a cold beer. My state is stable. My thread is committed. My checkpoint is secure.
The next time you build an agent, don’t just build a prompt. Build a memory. Build a system that can survive the storm.
Common Pitfalls / Error Logs
1. The “In-Memory” Trap
Using MemorySaver() in production. Error: Lost state after server restart. Log: No state found for thread_id ‘xxx’ after process reboot. Solution: Always use SqliteSaver or PostgresSaver in production.
2. State Explosion
Saving massive binary objects or entire HTML pages into the graph state. Error: Database write timeout or Context window exceeded. Solution: Store large data in a separate object store (S3) and only keep the URI in the LangGraph state.
3. Missing Thread ID
Log: ValueError: Config must contain thread_id for persistence. Solution: Ensure your config object always has a configurable key with a thread_id.
Comparison (The Architectural Matrix)
| Feature | LangGraph | Autogen | CrewAI | LangChain Chains | | | | | | | | State Management | Native Checkpointing | Manual / Event-based | Process-driven | Stateless / Buffer | | Persistence | Built-in DB savers | Custom implementation | 3rd-party integration | Manual persistence | | Control Flow | Cyclic Graph (Explicit) | Conversational | Hierarchical | Linear / Directed | | Human-in-the-loop | First-class Breakpoints | Interactive Chat | Task Approval | Not Native |
LangGraph is the choice for engineers who want absolute control over the state machine. Autogen is great for multi-agent brainstorming, but LangGraph is where you build the “Operating System” for your agents.
-
What is LangGraph checkpointing? It is a mechanism that snapshots the state of an agentic graph at every node transition and persists it to a database for recovery and human intervention.
-
Is checkpointing the same as memory? Checkpointing is a technical implementation of persistence. Memory is a broader concept that includes how the agent uses that persisted state to inform future decisions.
-
Should I use Postgres for LangGraph memory? Yes, for production workloads with multiple concurrent users, PostgresSaver is the gold standard for reliability and horizontal scaling.
-
Can LangGraph handle human approval? Absolutely. Using interrupt_before or interrupt_after, you can pause execution and wait for an external signal (human click) to resume.
-
How do I clear old checkpoints? You can use the delete method or set a TTL (Time to Live) on your database rows to prevent your storage from bloating over time.
- AI Agent Complete Guide: From Zero to Autonomous
- LangGraph Pillar Page: Mastering Stateful AI Agents
- AI Agent Memory Systems: From RAG to Persistence
- Building a Production AI Invoice Agent
- MCP vs Function Calling: Which one for your Tools?
- n8n AI Workflow Error Handling Guide
I am done for today. Guiyang’s rain has turned into a light mist. The NAS fan has finally calmed down. The state is saved. The thread is closed.
小白签名:为 Chunk 而写,为召回而生。
